如何使用qq邮箱做网站河南自助建站seo公司
文章目录
- 专栏导读
- 背景
- 结果预览
- 1、页面分析
- 2、通过返回数据发现适合利用lxml+xpath
- 3、进行Markdown语言拼接
- 总结
专栏导读
在这里插入图片描述
🔥🔥本文已收录于《Python基础篇爬虫》
🉑🉑本专栏专门
针对于有爬虫基础准备的一套基础教学,轻松掌握Python爬虫,欢迎各位同学订阅,专栏订阅地址:点我直达
🤞🤞此外如果您已工作,如需利用Python解决办公中常见的问题,欢
迎订阅《Python办公自动化》专栏,订阅地址:点我直达
的
🔺🔺此外《Python30天从入门到熟练》专栏已上线,欢迎大家订阅,订阅地址:点我直达
背景
-
我经常会将CSDN写过的某一专栏的其他文章转为Markdown列表,放入到新的文章中,这样方便友友们看到我之前的写的文章,然后点击链接即可跳转查看!!,我觉得这样非常方便
结果预览
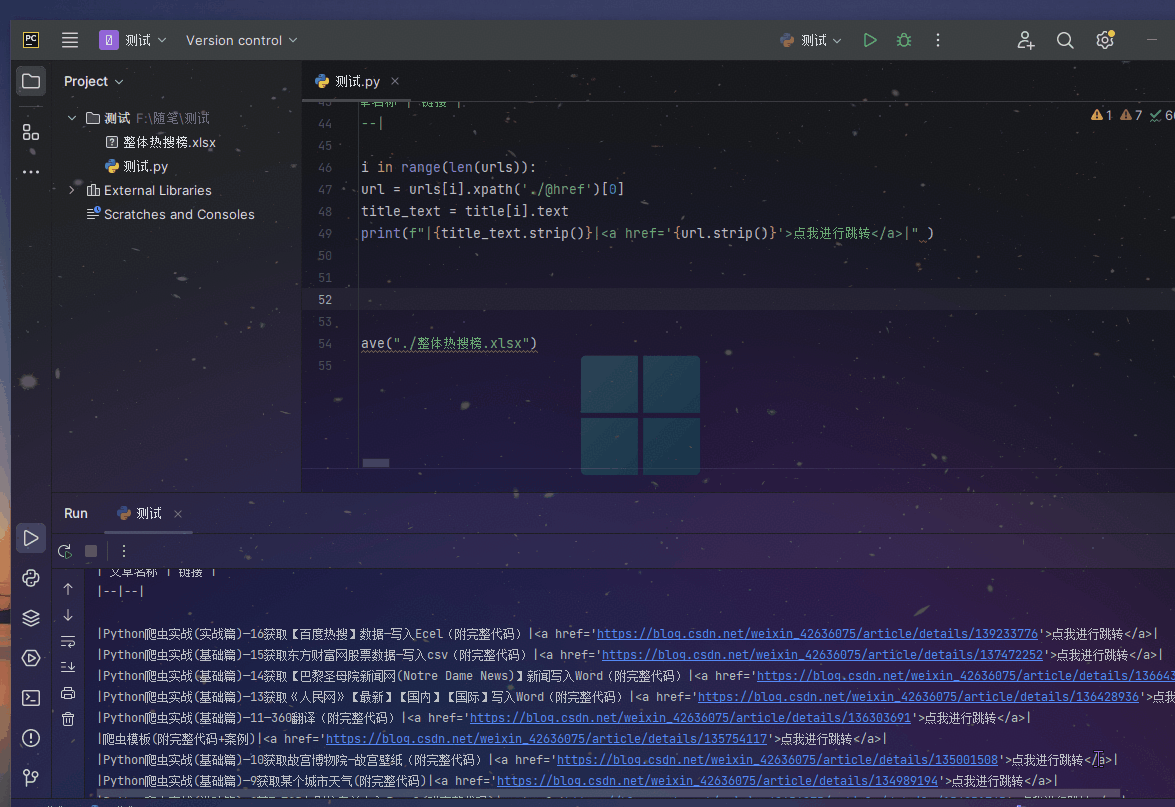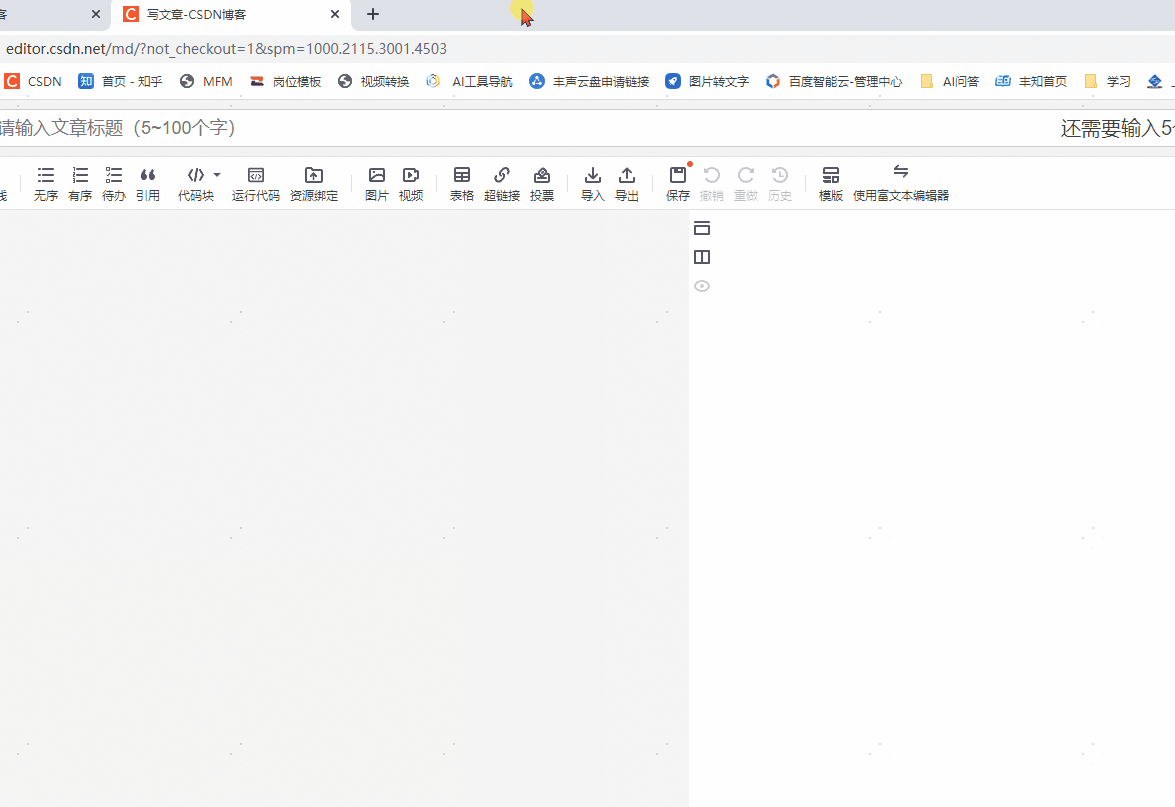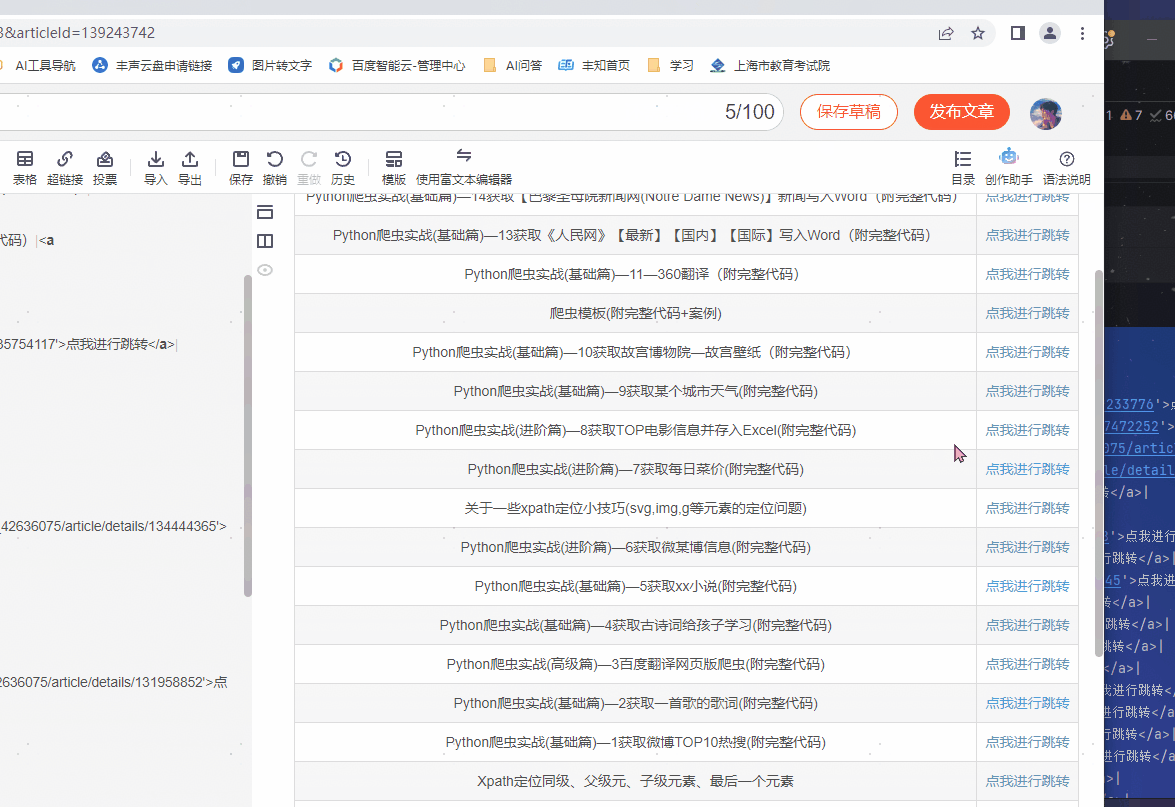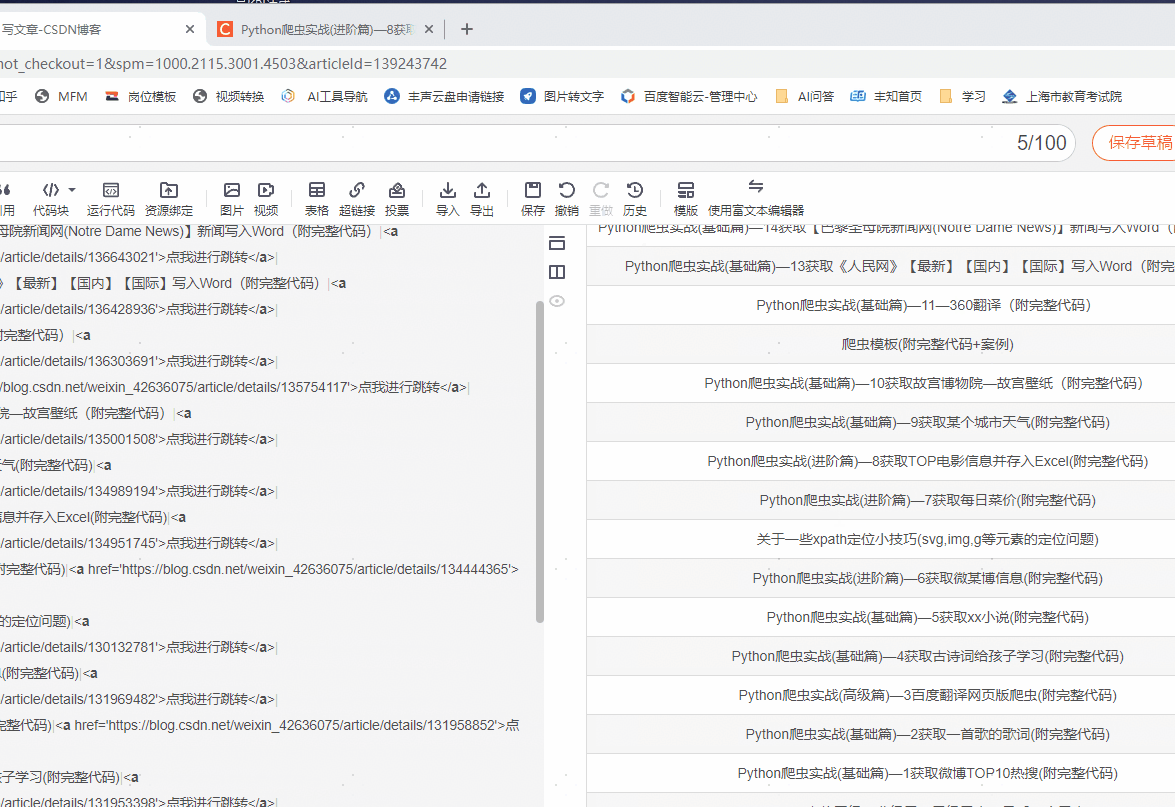
1、页面分析
-
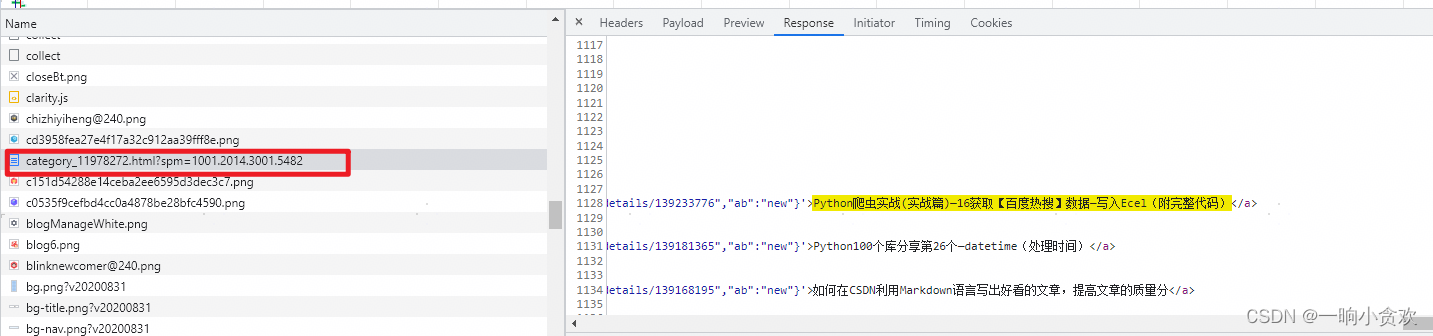
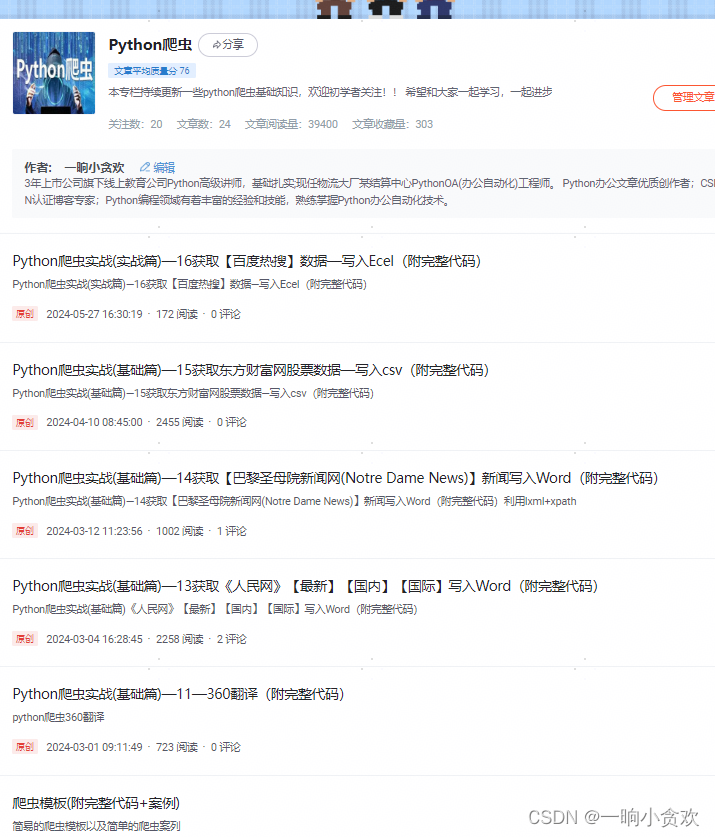
就以我的【爬虫专栏进行分析】
爬取URL:https://blog.csdn.net/weixin_42636075/category_11978272.html
爬取方法:GET
返回数据:整个页面(TXT)
-
初步代码
# -*- coding: UTF-8 -*-
'''
@Project :项目名称
@File :程序.py
@IDE :PyCharm
@Author :一晌小贪欢
@Date :2024/05/27 17:00
'''import json
import requests
from lxml import etreeurl = 'https://top.baidu.com/board?'
cookies = {'Cookie': '填写自己的Cookie',
}headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',}params = {
'spm': '1001.2014.3001.5482'
}res_data = requests.get(url=url, params=params, headers=headers, cookies=cookies)
res_data.encoding = "utf-8"
print(res_data.text)
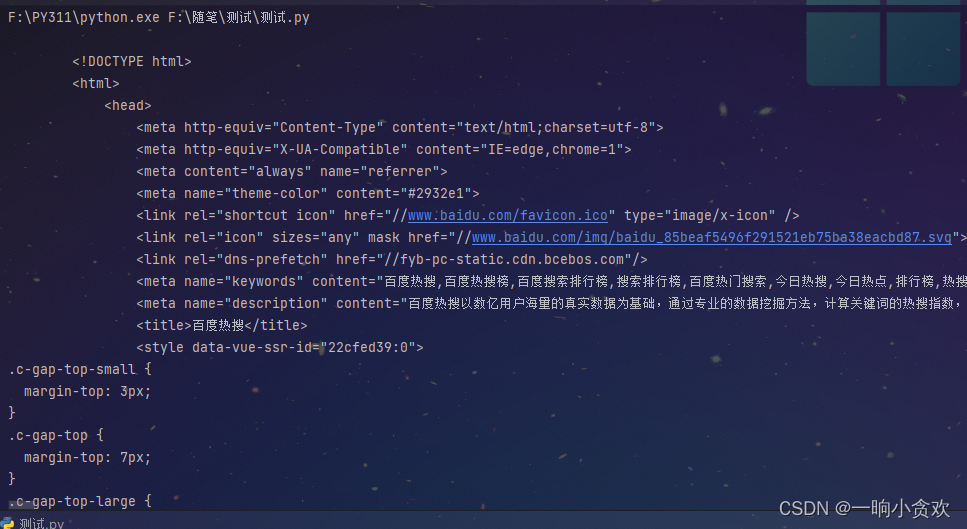
2、通过返回数据发现适合利用lxml+xpath
-
我们发现返回的数据是整个网页,其中每一个【文章标题】以及【文章链接】都在其中
-
经过分析得到,所有的 【文章标题】以及【文章链接】都在如下的xpath中 ↓
//ul[@class="column_article_list"]//li//a【文章链接】//ul[@class="column_article_list"]//li//div[@class="column_article_title"]//h2【文章标题】
3、进行Markdown语言拼接
-
搞定!!
-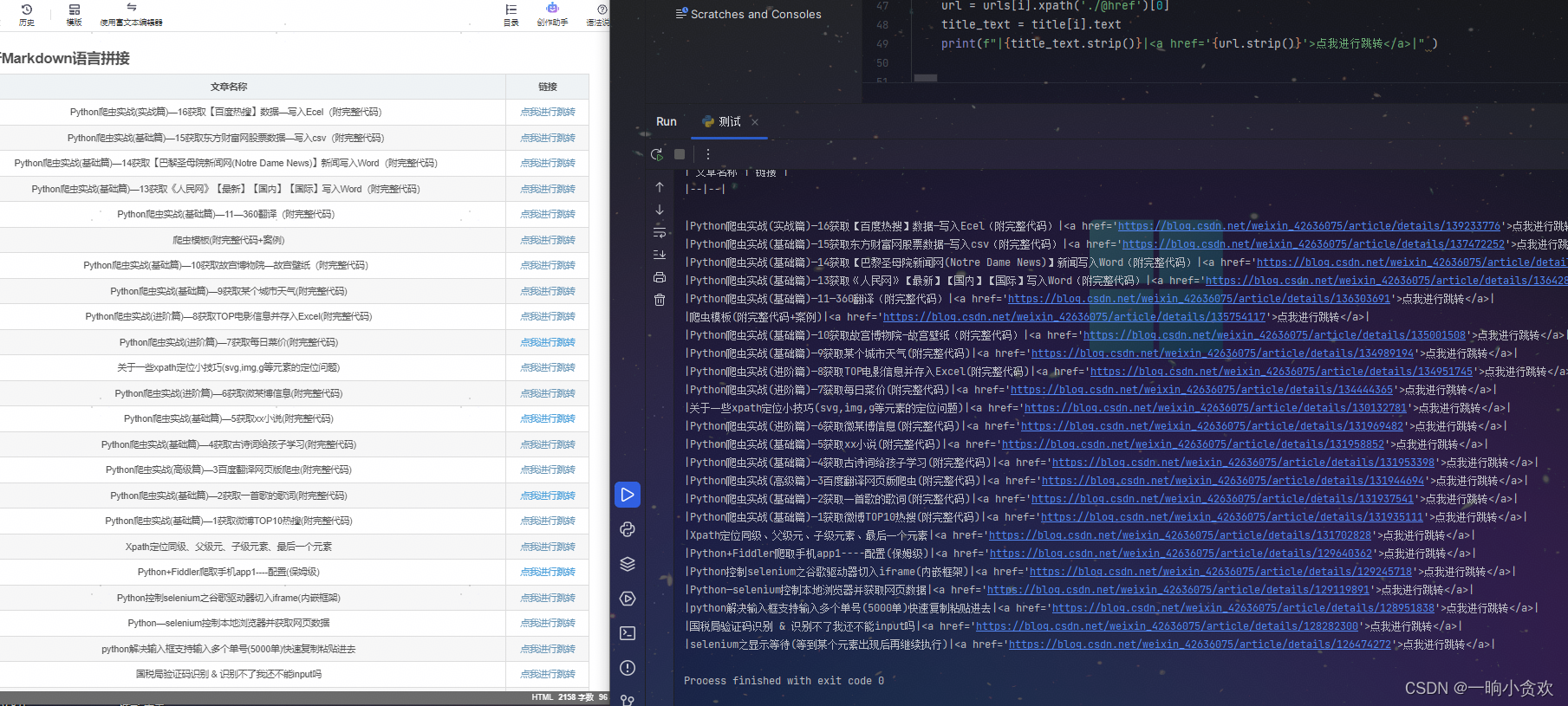
| 文章名称 | 链接 |
|---|---|
| Python爬虫实战(实战篇)—16获取【百度热搜】数据—写入Ecel(附完整代码) | 点我进行跳转 |
| Python爬虫实战(基础篇)—15获取东方财富网股票数据—写入csv(附完整代码) | 点我进行跳转 |
| Python爬虫实战(基础篇)—14获取【巴黎圣母院新闻网(Notre Dame News)】新闻写入Word(附完整代码) | 点我进行跳转 |
| Python爬虫实战(基础篇)—13获取《人民网》【最新】【国内】【国际】写入Word(附完整代码) | 点我进行跳转 |
| Python爬虫实战(基础篇)—11—360翻译(附完整代码) | 点我进行跳转 |
| 爬虫模板(附完整代码+案例) | 点我进行跳转 |
| Python爬虫实战(基础篇)—10获取故宫博物院—故宫壁纸(附完整代码) | 点我进行跳转 |
| Python爬虫实战(基础篇)—9获取某个城市天气(附完整代码) | 点我进行跳转 |
| Python爬虫实战(进阶篇)—8获取TOP电影信息并存入Excel(附完整代码) | 点我进行跳转 |
| Python爬虫实战(进阶篇)—7获取每日菜价(附完整代码) | 点我进行跳转 |
| 关于一些xpath定位小技巧(svg,img,g等元素的定位问题) | 点我进行跳转 |
| Python爬虫实战(进阶篇)—6获取微某博信息(附完整代码) | 点我进行跳转 |
| Python爬虫实战(基础篇)—5获取xx小说(附完整代码) | 点我进行跳转 |
| Python爬虫实战(基础篇)—4获取古诗词给孩子学习(附完整代码) | 点我进行跳转 |
| Python爬虫实战(高级篇)—3百度翻译网页版爬虫(附完整代码) | 点我进行跳转 |
| Python爬虫实战(基础篇)—2获取一首歌的歌词(附完整代码) | 点我进行跳转 |
| Python爬虫实战(基础篇)—1获取微博TOP10热搜(附完整代码) | 点我进行跳转 |
| Xpath定位同级、父级元、子级元素、最后一个元素 | 点我进行跳转 |
| Python+Fiddler爬取手机app1----配置(保姆级) | 点我进行跳转 |
| Python控制selenium之谷歌驱动器切入iframe(内嵌框架) | 点我进行跳转 |
| Python—selenium控制本地浏览器并获取网页数据 | 点我进行跳转 |
| python解决输入框支持输入多个单号(5000单)快速复制粘贴进去 | 点我进行跳转 |
| 国税局验证码识别 & 识别不了我还不能input吗 | 点我进行跳转 |
| selenium之显示等待(等到某个元素出现后再继续执行) | 点我进行跳转 |
总结
-
希望对初学者有帮助
-
致力于办公自动化的小小程序员一枚
-
希望能得到大家的【一个免费关注】!感谢
-
求个 🤞 关注 🤞
-
此外还有办公自动化专栏,欢迎大家订阅:Python办公自动化专栏
-
求个 ❤️ 喜欢 ❤️
-
此外还有爬虫专栏,欢迎大家订阅:Python爬虫基础专栏
-
求个 👍 收藏 👍
-
此外还有Python基础专栏,欢迎大家订阅:Python基础学习专栏